Links
- Dissertation (Coming Soon!)
Abstract
This dissertation investigates methods for incorporating robotic domain knowledge into deep learning systems to represent different action spaces. Robots can be controlled through action spaces spanning different levels of abstraction, from low-level joint torques to high-level Cartesian poses. Beyond physical action spaces, latent action spaces offer learned embeddings that coordinate atomic commands into coherent patterns—motivated by the manifold hypothesis that robot actions often lie on lower-dimensional manifolds. A key limitation of existing latent action space learning is that current models often ignore available prior knowledge, requiring substantially more data than approaches that explicitly encode motion structure. Our hypothesis is that encoding robotic priors into deep learning architectures improves performance for both autonomous agents and human operators interacting with the system.
We present three primary contributions toward this goal. First, we develop local-linear neural networks that explicitly encode human priors in teleoperation systems. This architecture has nonlinear transformations of robot-state variables but behaves linearly with respect to user inputs, enforcing scalability, consistency, reversibility, and controllability. Our user studies demonstrate significant improvements over alternative deep learning systems and provide a more interpretable framework for explaining human success rates. Second, we incorporate Bayesian aggregation with neural networks to develop more robust deep learning movement primitives that perform well with less data on real robot systems while offering greater flexibility in specifying motor-primitive skills. Third, we improve the transferability of cross-embodiment control policies that leverage a robot’s topological structure, showing that transfer often requires specialization to the target embodiment and can be adjusted to fit available compute resources.
Our work develops neural architectures with robot domain knowledge spanning spatial relations, temporal interactions, and robot topological structure. These contributions highlight the significant role domain knowledge continues to play in developing robot learning systems that generalize well to changing situations. This work represents a step toward better modular deep learning components that are interpretable, data-efficient, and reusable across different robotic platforms and tasks.
Teleoperation (Chapter 3 & 4)
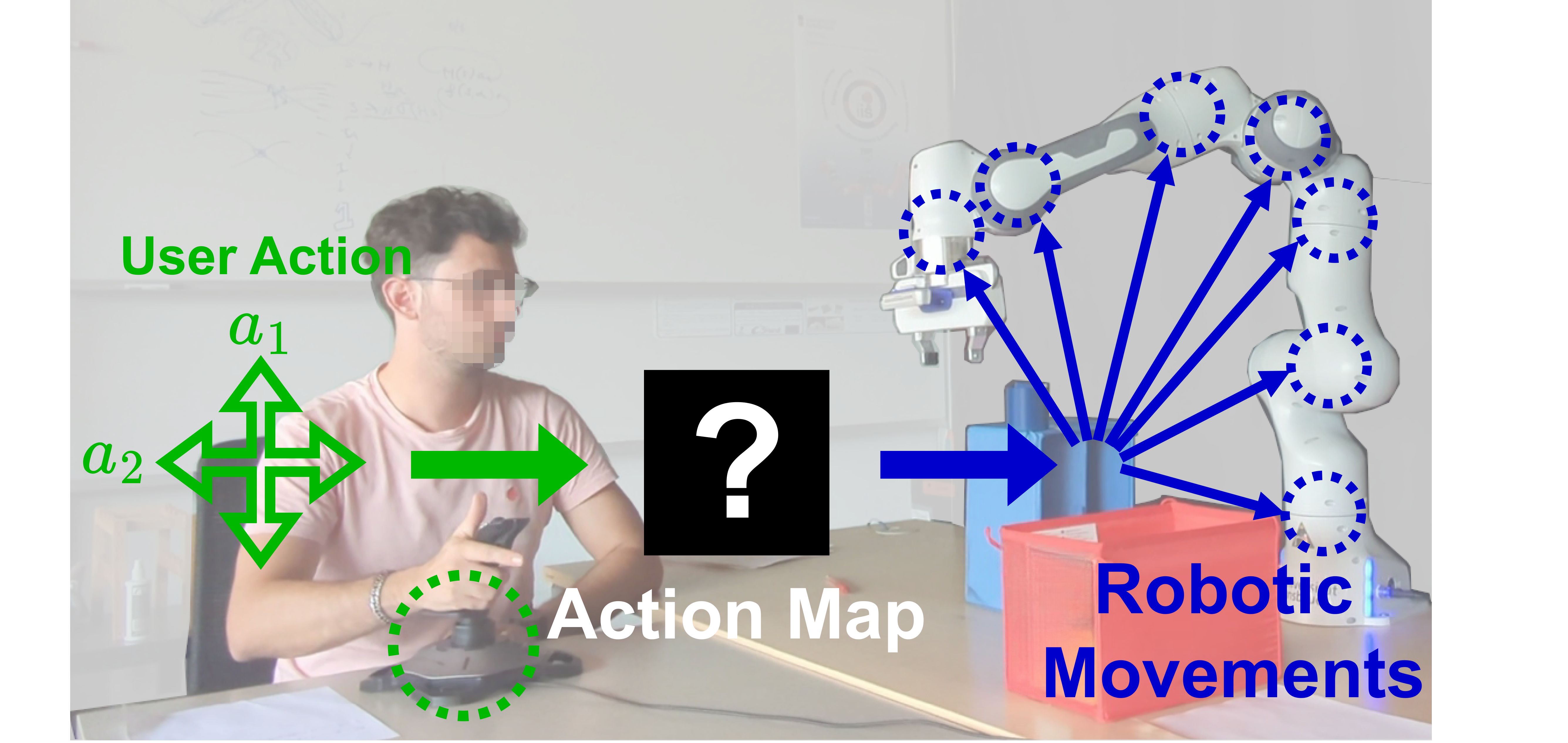
This work addresses the core challenge of limited-degree-of-freedom (DOF) teleoperation, where users — such as people with disabilities operating a wheelchair-mounted robotic arm — must control a high-DOF robot through a low-DOF interface like a 2D joystick. Rather than relying on traditional Cartesian mode-switching, which places significant cognitive burden on the user, we develop neural action maps that learn latent representations to re-map low-dimensional user inputs into task-relevant robot commands. A central contribution is the state-conditioned linear (SCL) architecture — a local-linear neural network that behaves linearly with respect to user inputs while using nonlinear state transformations, enforcing desirable properties like scalability, consistency, reversibility, and controllability. A later simplification of this system, DeepPCA, uses deep principal component analysis to derive these mappings more efficiently. Extensive user studies with 52 participants across multiple manipulation tasks empirically validated these systems, demonstrating significant improvements in task success rates and completion times over both prior deep learning approaches and conventional mode-switching baselines, while also providing a more interpretable framework for understanding human performance.
Figure 3.1 : User teleoperating a 7-DOF robot using a 2D joystick with a data-driven spatial mapping interface.
Movement Primitives (Chapter 5)
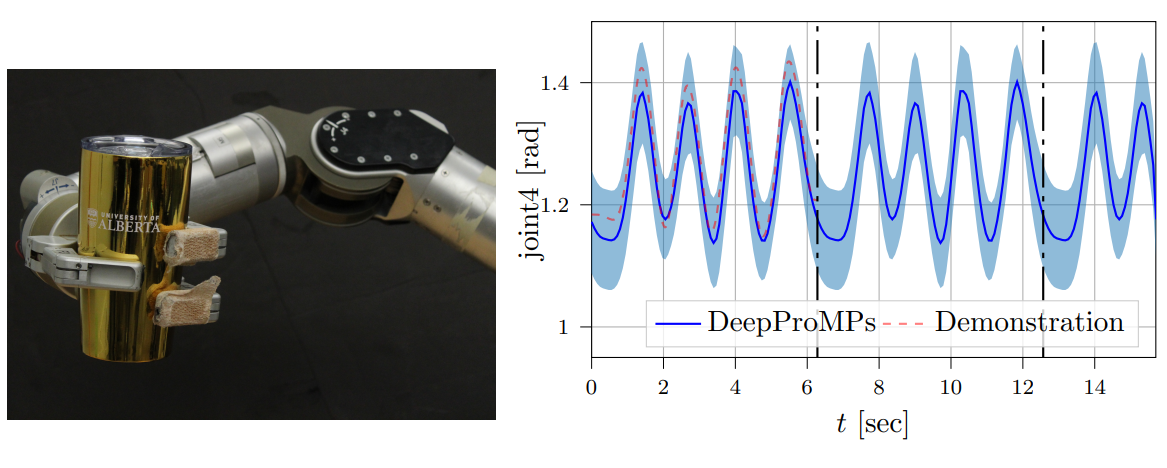
This chapter presents Deep Probabilistic Movement Primitives (DeepProMP), a novel learning-from-demonstration framework that extends classical Probabilistic Movement Primitives (ProMPs) using deep learning. Traditional ProMPs model distributions over robot trajectories using a linear-Gaussian framework, which limits them to uni-modal movement distributions and constrains their expressiveness on complex, multi-modal tasks. DeepProMP overcomes this by representing motion primitives as a latent variable distribution decoded by a neural network, trained with variational inference — capturing richer, multi-modal motion structure while retaining the key ProMP capabilities of conditioning on via-points and external variables to generalize to novel task configurations. By incorporating Bayesian aggregation into the neural network architecture, the model achieves greater robustness and data efficiency, performing well with fewer demonstrations on real robot hardware while offering significantly more flexibility in specifying movement goals than its linear predecessor.
Figure 5.5: Left: Experimental setup of Make Mojito. Right: Demonstrated motion and learned cyclical behaviour. Results demonstrate that DeepProMPS can smoothly repeat cyclical motions indefinitely.
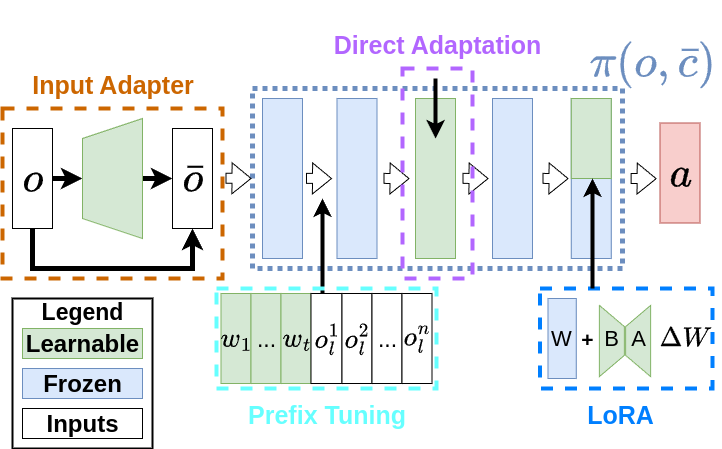
Cross Embodiment Policy Transfer (Chapter 6)
This chapter investigates morphology-aware policy transfer — the problem of learning control policies that generalize across robots with different physical bodies (morphologies), reducing the need to train from scratch on every new embodiment. The work frames this as a contextual Markov decision process where morphology information (e.g., limb connectivity, joint configurations) serves as context, allowing a single policy to reason across a distribution of robot designs. A key challenge is that while morphology-aware pretraining enables cross-embodiment generalization, it may sacrifice peak performance on any single target robot. To address this, the chapter explores Parameter-Efficient Fine-Tuning (PEFT) algorithms — borrowed from the large language model literature — as a compute-efficient means of adapting pretrained morphology-aware policies to specific target embodiments at deployment, where computational resources may be limited. The results provide empirical insight into which PEFT strategies best balance generalization and specialization in online reinforcement learning settings.